

format_list_bulleted Contenido
VaultGemma: El modelo de lenguaje más grande del mundo entrenado con privacidad diferencial. Descubre cómo Google revoluciona la IA privada.

En la era digital actual, donde cada clic, cada búsqueda y cada conversación queda registrada en algún servidor, la privacidad se ha convertido en un bien preciado. ¿Alguna vez te has preguntado qué pasa con tus datos cuando interactúas con esos modelos de lenguaje tan inteligentes que parecen saberlo todo? La respuesta, hasta ahora, no era muy alentadora.
security Un Cambio de Paradigma
Google Research ha dado un paso monumental con el lanzamiento de VaultGemma, el modelo de lenguaje más grande del mundo (1B parámetros) entrenado desde cero con privacidad diferencial. Este avance no es solo una hazaña técnica; representa un cambio fundamental en cómo podemos interactuar con la inteligencia artificial sin sacrificar nuestra privacidad. ¿Estamos presenciando el nacimiento de una nueva generación de IA que respeta nuestros derechos fundamentales?
VaultGemma nace en un momento crítico. Cada día escuchamos noticias sobre filtraciones de datos, uso indebido de información personal y modelos de IA que memorizan detalles sensibles de sus conjuntos de entrenamiento. La situación se ha vuelto tan preocupante que expertos de Stanford HAI advierten sobre los riesgos de un "ecosistema digital donde nuestra información personal está expuesta sin control". En este contexto, VaultGemma no es solo una innovación técnica, sino una respuesta necesaria a uno de los mayores desafíos de nuestro tiempo.
shield ¿Qué es la Privacidad Diferencial?
Antes de sumergirnos en los detalles de VaultGemma, es crucial entender el concepto que lo hace posible: la privacidad diferencial (DP). Imagina que estás en una habitación llena de gente y quieres saber el promedio de edad sin que nadie sepa cuántos años tienes tú específicamente. La privacidad diferencial es como añadir un poco de "ruido" a las respuestas individuales antes de calcular el promedio, asegurando que tu contribución específica no pueda ser identificada.
science La Matemática Detrás de la Privacidad
Formalmente, la privacidad diferencial proporciona una garantía matemática rigurosa de que el resultado de un análisis no revelará si un individuo específico participó en el conjunto de datos. En el contexto de los modelos de lenguaje, esto significa que el modelo no memorizará información específica de ningún documento o usuario en particular. ¿Suena complicado? En realidad es bastante elegante: al agregar ruido calibrado durante el entrenamiento, aseguramos que el modelo aprenda patrones generales sin retener detalles específicos que podrían comprometer la privacidad.
Pero aquí viene lo interesante: aplicar privacidad diferencial a modelos de lenguaje grandes no es tarea fácil. Los modelos de IA modernos son increíblemente sedientos de datos y requieren enormes cantidades de información para aprender. ¿Cómo equilibramos la necesidad de datos con la protección de la privacidad? Esta es precisamente la pregunta que Google Research se propuso responder con VaultGemma.
"La privacidad diferencial permite a los modelos de lenguaje aprender patrones útiles del mundo sin ser influenciados indebidamente por ningún documento o dato de usuario específico, mitigando fundamentalmente el riesgo de filtraciones de privacidad del corpus de entrenamiento original." - Informe Técnico de VaultGemma
memory VaultGemma: El Modelo

VaultGemma 1B es mucho más que un simple modelo de lenguaje; es un testimonio de lo que es posible cuando la innovación técnica se alinea con los principios éticos. Basado en la arquitectura de los modelos Gemma de Google, VaultGemma fue entrenado desde cero utilizando privacidad diferencial, logrando algo que hasta hace poco parecía imposible: un modelo de lenguaje grande y potente que respeta la privacidad de los datos con los que fue entrenado.
architecture Especificaciones Técnicas
- Parámetros: 1 mil millones (1B)
- Arquitectura: Transformer solo-decodificador
- Longitud de secuencia: 1024 tokens
- Atención: Global en todas las capas
- Normalización: RMSNorm para estabilizar el entrenamiento
- Vocabulario: 256K entradas
- Garantía de privacidad: (ε ≤ 2.0, δ ≤ 1.1e-10) a nivel de secuencia
Una de las decisiones técnicas más interesantes fue reducir la longitud de secuencia a 1024 tokens. ¿Por qué? Porque esto permite reducir significativamente los requisitos de cómputo, lo que a su vez permite usar tamaños de lote más grandes, una necesidad crítica para un buen rendimiento en entrenamiento privado. Es un ejemplo perfecto de cómo los compromisos inteligentes en el diseño pueden llevar a resultados excepcionales.
Entrenamiento con Privacidad Diferencial
code DP-SGD y Escalabilidad
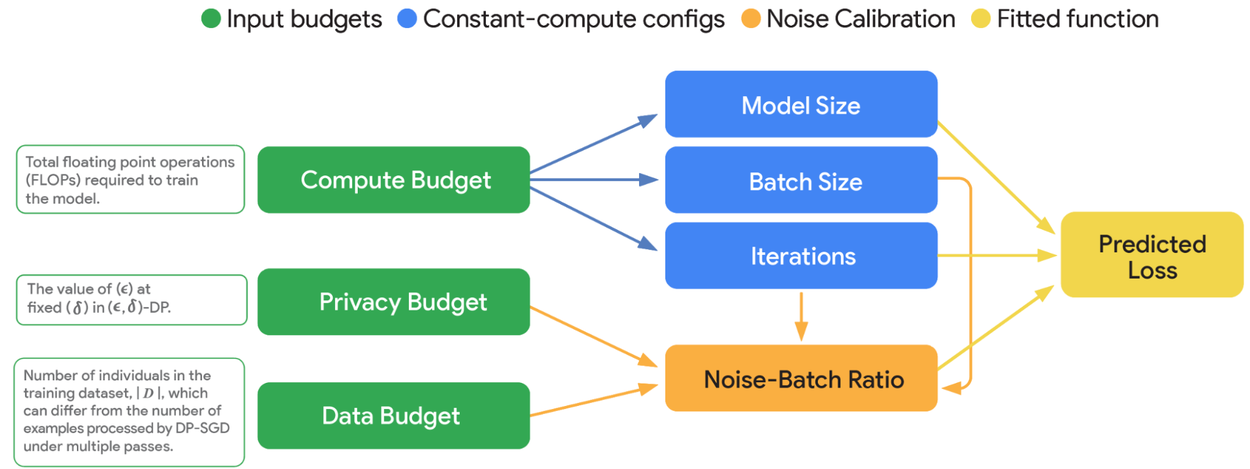
El equipo de VaultGemma implementó DP-SGD (Descenso de Gradiente Estocástico Diferencialmente Privado) sobre la tubería de preentrenamiento de Gemma. Pero aquí viene lo realmente innovador: desarrollaron nuevas leyes de escalabilidad que modelan con precisión las complejidades del entrenamiento de modelos de lenguaje con privacidad diferencial. Estas leyes proporcionan una imagen completa de las compensaciones entre cómputo-privacidad-utilidad y las configuraciones óptimas de entrenamiento.
¿Y qué significa todo esto en la práctica? Significa que VaultGemma fue entrenado con una garantía matemática rigurosa de que no memorizará información específica de ningún documento o usuario. Si información relacionada con cualquier hecho o inferencia (potencialmente privada) ocurre en una sola secuencia, entonces VaultGemma esencialmente no sabrá ese hecho: la respuesta a cualquier consulta será estadísticamente similar al resultado de un modelo que nunca se entrenó con la secuencia en cuestión.
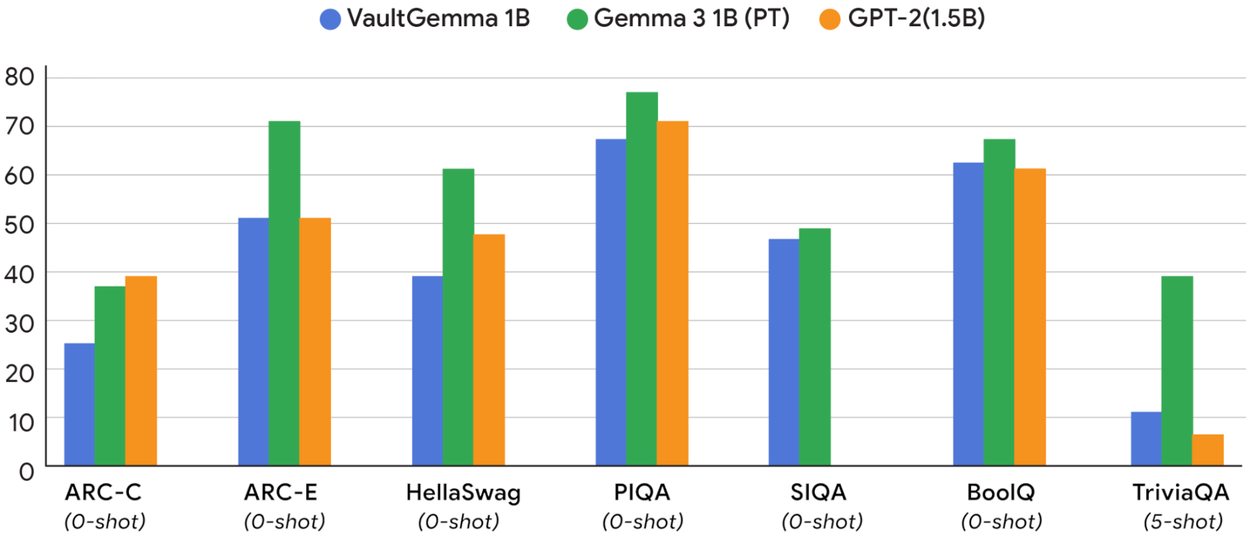
En términos de rendimiento, VaultGemma se compara favorablemente con modelos no privados de hace aproximadamente cinco años, como GPT-2. Aunque todavía existe una brecha de utilidad entre los modelos entrenados con privacidad diferencial y los que no lo están, el trabajo de Google demuestra que esta brecha puede cerrarse sistemáticamente con más investigación en el diseño de mecanismos para el entrenamiento con privacidad diferencial.
engineering Desafíos Superados
Crear VaultGemma no fue un camino de rosas. El equipo de Google Research enfrentó numerosos desafíos técnicos que hasta ahora parecían insuperables. Uno de los mayores obstáculos fue el manejo del muestreo de Poisson, un componente central del DP-SGD que crea lotes de diferentes tamaños y requiere un orden específico y aleatorio para procesar los datos.
lightbulb Innovación en el Procesamiento de Datos
Para superar este desafío, el equipo desarrolló Scalable DP-SGD, un método que permite procesar datos en lotes de tamaño fijo, ya sea añadiendo relleno adicional o recortándolos, mientras mantiene fuertes protecciones de privacidad. Esta innovación fue crucial para hacer el entrenamiento a gran escala con privacidad diferencial computacionalmente factible.
Leyes de Escalabilidad para Privacidad Diferencial
Quizás el avance más significativo fue el desarrollo de nuevas leyes de escalabilidad específicamente para modelos de lenguaje con privacidad diferencial. Estas leyes establecen que la pérdida predicha puede modelarse con precisión utilizando principalmente el tamaño del modelo, las iteraciones y la relación ruido-lote. Este entendimiento profundo permitió al equipo determinar cuánto cómputo necesitaban para entrenar un modelo Gemma de 1B parámetros con privacidad diferencial, y cómo asignar ese cómputo entre tamaño de lote, iteraciones y longitud de secuencia para lograr la mejor utilidad.
insights Hallazgos Clave
- Se debe entrenar un modelo mucho más pequeño con un tamaño de lote mucho más grande de lo que se usaría sin privacidad diferencial.
- Aumentar el presupuesto de privacidad de forma aislada lleva a rendimientos decrecientes, a menos que se combine con un aumento correspondiente en el presupuesto de cómputo o de datos.
- Existe flexibilidad en las configuraciones de entrenamiento: una variedad de tamaños de modelo puede proporcionar una utilidad muy similar si se combina con el número correcto de iteraciones y/o tamaño de lote.
Estos hallazgos no son solo teóricos; tienen implicaciones prácticas inmediatas para cualquier investigador o empresa que busque desarrollar modelos de lenguaje con garantías de privacidad. Por primera vez, tenemos un mapa claro y confiable para el desarrollo futuro de modelos privados.
trending_up Impacto en el Futuro de la IA

El lanzamiento de VaultGemma no es solo un logro técnico; es un hito en el camino hacia una IA más responsable y respetuosa con la privacidad. Al ser un modelo de código abierto, Google está democratizando el acceso a tecnologías de privacidad avanzada, permitiendo que investigadores, desarrolladores y empresas de todos los tamaños construyan aplicaciones de IA que no comprometan la privacidad de los usuarios.
public Aplicaciones en el Mundo Real
¿Dónde podríamos ver VaultGemma y sus sucesores en acción? Las posibilidades son emocionantes:
- Servicios de salud: Modelos que pueden analizar registros médicos sin exponer información sensible de pacientes.
- Servicios financieros: Sistemas que detectan fraudes sin memorizar datos de transacciones individuales.
- Educación: Tutores de IA que se adaptan a las necesidades de los estudiantes sin retener información personal.
- Asistentes personales: Ayudantes de IA que realmente respetan tu privacidad en lugar de vender tus datos a los mejores postores.
Cerrando la Brecha de Privacidad
Uno de los aspectos más importantes de VaultGemma es que demuestra que la brecha entre los modelos de lenguaje privados y no privados puede cerrarse sistemáticamente. Actualmente, VaultGemma tiene un rendimiento comparable al de modelos no privados de hace aproximadamente cinco años, pero este es solo el comienzo. Con más investigación y desarrollo, podemos esperar que esta brecha se reduzca aún más, acercándonos a un futuro donde los modelos de lenguaje puedan ser tanto potentes como respetuosos con la privacidad.
policy Implicaciones Regulatorias
En un mundo donde las regulaciones de privacidad como el GDPR en Europa y el CCPA en California se vuelven cada vez más estrictas, VaultGemma ofrece un camino a seguir para las empresas que buscan cumplir con estas normativas sin sacrificar el rendimiento de sus sistemas de IA. ¿Podríamos ver un futuro donde la privacidad diferencial no sea solo una opción técnica, sino un requisito legal para los sistemas de IA?
play_circle VaultGemma en Acción
Para comprender mejor el impacto de VaultGemma, te invitamos a ver este video que resume su lanzamiento y sus implicaciones para el futuro de la IA privada:
auto_awesome Conclusión: Un Paso Adelante
VaultGemma representa mucho más que un avance técnico; es un testimonio del compromiso de la comunidad de IA con la construcción de tecnología que no solo sea potente, sino también ética y respetuosa con los derechos fundamentales de las personas. En un mundo donde cada vez más aspectos de nuestras vidas están mediados por la tecnología, la privacidad no es un lujo, sino una necesidad.
psychology Reflexión Final
¿Qué nos dice VaultGemma sobre el futuro de la IA? Nos dice que no tenemos que elegir entre rendimiento y privacidad. Nos dice que la innovación técnica y la responsabilidad ética pueden ir de la mano. Y sobre todo, nos dice que el futuro de la IA puede ser uno donde la tecnología sirva a las personas, no al revés.
Como sociedad, estamos en un punto crucial. Las decisiones que tomemos hoy sobre cómo desarrollamos y desplegamos la IA tendrán repercusiones durante generaciones. Iniciativas como VaultGemma nos muestran un camino forward, un camino donde la tecnología avanza sin dejar atrás nuestros valores más fundamentales.
El camino por delante todavía es largo. La brecha de rendimiento entre los modelos privados y no privados, aunque se está cerrando, todavía existe. Pero por primera vez, tenemos un mapa claro y las herramientas necesarias para continuar este viaje. VaultGemma no es el destino final; es solo el comienzo de una nueva era de IA que respeta nuestra privacidad.
"VaultGemma representa un paso significativo en el camino hacia la construcción de IA que es a la vez potente y privada por diseño. Esperamos que VaultGemma y nuestra investigación acompañante capaciten a la comunidad para construir la próxima generación de IA segura, responsable y privada para todos." - Equipo de VaultGemma, Google Research
Mientras reflexionamos sobre el impacto de VaultGemma, surge una pregunta inevitable: ¿estamos listos para abrazar un futuro donde la privacidad no sea una opción, sino un componente fundamental de toda la tecnología que desarrollamos? La respuesta a esta pregunta definirá no solo el futuro de la IA, sino el futuro de nuestra relación con la tecnología en general.
En última instancia, VaultGemma es más que un modelo de lenguaje; es un recordatorio de que la tecnología puede ser una fuerza para el bien, una herramienta que amplifica nuestras capacidades sin comprometer nuestros derechos. Y en un mundo donde la privacidad parece estar constantemente bajo amenaza, eso es algo que vale la pena celebrar.


