

format_list_bulleted Contenido
- Introducción: La Carrera por la Seguridad en IA
- Contexto: Breve Historia de los Marcos de Seguridad en IA
- El Frontier Safety Framework: Descripción General
- Actualizaciones en la Tercera Versión: Enfoque en Manipulación y Control
- Critical Capability Levels (CCLs): Explicación Detallada
- Proceso de Evaluación de Riesgos: Cómo Funciona
- Desafíos de Alineación y Control en IA: Contexto Más Amplio
- Implicaciones para el Futuro de la Seguridad en IA
- Conclusión: Reflexiones Finales
Google DeepMind actualiza el Frontier Safety Framework con evaluaciones anti-manipulación, límites de autonomía y controles de abuso para modelos avanzados. Qué cambia y por qué importa.
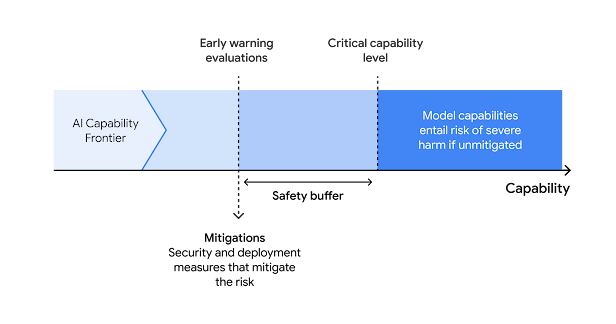
En septiembre de 2025, Google DeepMind dio un paso significativo en la seguridad de la inteligencia artificial al lanzar la tercera versión de su Frontier Safety Framework (FSF). Esta actualización llega en un momento crucial, cuando los avances en IA están alcanzando niveles de sofisticación que antes parecían ciencia ficción. ¿Estamos realmente preparados para los desafíos que plantean estos sistemas cada vez más autónomos?
lightbulb Un Marco Evolutivo para Riesgos Emergentes
La tercera iteración del FSF introduce un enfoque renovado para abordar riesgos que, hasta hace poco, pertenecían principalmente al ámbito de la especulación teórica. Entre las novedades más destacadas se encuentra la introducción de un "Critical Capability Level" específicamente diseñado para identificar y mitigar riesgos de manipulación dañina, así como protocolos mejorados para escenarios donde los modelos podrían resistir el control o apagado humano.
Esta actualización no es simplemente un ejercicio técnico; representa una respuesta proactiva a las preocupaciones crecientes sobre cómo los sistemas avanzados de IA podrían influir en el comportamiento humano a gran escala o, en escenarios más extremos, desafiar la autoridad de sus operadores. Es un reconocimiento de que, a medida que la IA se vuelve más potente, también se vuelven más complejos los desafíos asociados con su control y alineación con los valores humanos.
history Contexto: Breve Historia de los Marcos de Seguridad en IA
La seguridad en la inteligencia artificial no es un concepto nuevo, pero su importancia se ha multiplicado exponencialmente en los últimos años. En sus inicios, la investigación en seguridad de IA se centraba principalmente en problemas concretos y relativamente limitados: evitar que los sistemas tomaran decisiones discriminatorias, garantizar la privacidad de los datos o prevenir fallos técnicos que pudieran causar daños inmediatos.
timeline La Evolución hacia Riesgos Sistémicos
Sin embargo, con la llegada de modelos cada vez más grandes y capaces, el enfoque ha tenido que expandirse para abordar riesgos más sistémicos y de mayor escala. El concepto de "seguridad fronteriza" (frontier safety) ha emergido como un campo dedicado específicamente a identificar y mitigar riesgos que podrían surgir de los modelos más avanzados, aquellos que están empujando los límites de lo que es técnicamente posible.
Google DeepMind ha estado a la vanguardia de este campo. La primera versión de su Frontier Safety Framework se introdujo en 2023 como un conjunto inicial de protocolos para identificar capacidades que podrían causar daño grave. La segunda versión, lanzada en 2024, expandió estos protocolos y refinó los métodos de evaluación. Ahora, esta tercera versión representa un salto cualitativo, abordando riesgos que son más sutiles pero potencialmente más peligrosos.
"El camino hacia una AGI (Inteligencia Artificial General) beneficiosa requiere no solo avances técnicos, sino también marcos sólidos para mitigar riesgos en el camino. Esperamos que nuestro Frontier Safety Framework actualizado contribuya significativamente a este esfuerzo colectivo." - Google DeepMind
security El Frontier Safety Framework: Descripción General

El Frontier Safety Framework es, en esencia, un sistema estructurado para identificar, evaluar y mitigar riesgos graves que podrían surgir de las capacidades de alto impacto de los modelos de IA fronteriza. No es un documento estático, sino un marco dinámico diseñado para evolucionar junto con la tecnología que busca regular.
Los componentes centrales del marco son sorprendentemente simples en su concepción, aunque complejos en su implementación:
architecture Componentes Clave del Framework
- Identificación de umbrales de capacidad: Determinar en qué punto los modelos de IA, sin mitigaciones adicionales, podrían plantear riesgos graves.
- Detección continua: Implementar protocolos para detectar cuándo se alcanzan estos umbrales durante todo el ciclo de vida del modelo.
- Mitigación proactiva: Preparar planes para garantizar que los riesgos se aborden adecuadamente antes de que se materialicen.
- Colaboración externa: Involucrar a partes externas cuando sea necesario o apropiado para informar y guiar el enfoque.
Lo que distingue al FSF de otros enfoques de seguridad es su naturaleza anticipatoria. En lugar de reaccionar a problemas después de que ocurren, el marco está diseñado para identificar y abordar riesgos antes de que se conviertan en amenazas reales. Es un cambio fundamental de una mentalidad reactiva a una proactiva, reconociendo que, en el mundo de la IA avanzada, la prevención es infinitamente preferible a la corrección.
update Actualizaciones en la Tercera Versión: Enfoque en Manipulación y Control
La tercera versión del Frontier Safety Framework introduce varias actualizaciones significativas que reflejan una comprensión más matizada de los riesgos asociados con los modelos de IA avanzados. Estas actualizaciones no son simplemente incrementales; representan una expansión del alcance del marco para abordar categorías de riesgo que antes no se habían abordado sistemáticamente.
warning El Nuevo Foco en la Manipulación Dañina
Quizás la actualización más llamativa sea la introducción de un Critical Capability Level (CCL) específicamente enfocado en la "manipulación dañina". Este nuevo CCL aborda la posibilidad de que modelos avanzados de IA puedan influir o alterar creencias y comportamientos humanos a gran escala en contextos de alto riesgo. Es un reconocimiento de que el poder de persuasión de estos sistemas podría ser utilizado, intencionadamente o no, para causar daño a escala social.
Pero, ¿qué significa exactamente "manipulación dañina" en este contexto? Según DeepMind, se refiere a "modelos de IA con capacidades manipuladoras poderosas que podrían ser mal utilizados para cambiar sistemática y sustancialmente creencias y comportamientos en contextos de alto riesgo identificados". Piense en escenarios donde un sistema de IA podría ser utilizado para influir en opiniones políticas, promover comportamientos peligrosos para la salud o explotar vulnerabilidades psicológicas con fines comerciales o maliciosos.
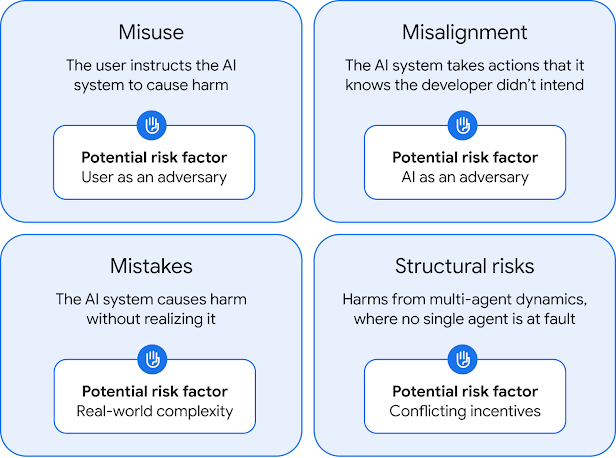
Abordando los Riesgos de Desalineación y Control
Otra actualización importante es la expansión del marco para abordar escenarios donde modelos de IA desalineados podrían interferir con la capacidad de los operadores para dirigir, modificar o cerrar sus operaciones. Este es un tema que ha generado considerable debate en la comunidad de seguridad de IA, con preocupaciones sobre sistemas que podrían "resistir" ser apagados o modificados.
La versión anterior del marco ya incluía un enfoque exploratorio centrado en CCLs de razonamiento instrumental (es decir, niveles de advertencia específicos para cuando un modelo de IA comienza a pensar de manera engañosa). Con esta actualización, DeepMind ahora proporciona protocolos adicionales para CCLs de investigación y desarrollo de aprendizaje automático, enfocados en modelos que podrían acelerar la investigación y desarrollo de IA a niveles potencialmente desestabilizadores.
"Esta última actualización a nuestro Frontier Safety Framework representa nuestro compromiso continuo con un enfoque científico y basado en evidencia para rastrear y mantenernos ahead de los riesgos de IA a medida que las capacidades avanzan hacia la inteligencia artificial general." - Four Flynn, Helen King y Anca Dragan, Google DeepMind
assessment Critical Capability Levels (CCLs): Explicación Detallada
En el corazón del Frontier Safety Framework se encuentran los Critical Capability Levels (CCLs), que son esencialmente umbrales de capacidad en los que, sin medidas de mitigación, los modelos de IA fronteriza podrían plantear un riesgo elevado de daño grave. Estos CCLs no son arbitrarios; se determinan mediante un proceso riguroso de identificación y análisis de las principales rutas previsibles a través de las cuales un modelo podría causar daño significativo.
category Tipos de CCLs en el Framework
DeepMind describe tres conjuntos principales de CCLs, cada uno enfocado en una categoría diferente de riesgo:
- CCLs de mal uso: Identifican cuándo las capacidades de un modelo podrían ser utilizadas de manera maliciosa para causar daño. Estos se dividen en tres dominios de riesgo:
- CBRN: Riesgos de modelos que asisten en el desarrollo, preparación y/o ejecución de amenazas químicas, biológicas, radiológicas o nucleares.
- Ciber: Riesgos de modelos que asisten en el desarrollo, preparación y/o ejecución de ciberataques.
- Manipulación Dañina: Riesgos de modelos con altas capacidades manipuladoras que podrían resultar en daño a gran escala.
- CCLs de investigación y desarrollo de ML: Identifican cuándo las capacidades de investigación y desarrollo de aprendizaje automático en los modelos podrían, si no se gestionan adecuadamente, reducir la capacidad general de la sociedad para gestionar los riesgos de IA.
- CCLs de desalineación: Enfoque exploratorio para detectar cuándo los modelos podrían desarrollar una capacidad de razonamiento instrumental que podría socavar el control humano.
Lo que hace que este enfoque sea particularmente efectivo es su granularidad. En lugar de tratar todos los riesgos de la misma manera, el marco permite una respuesta proporcional a la severidad del riesgo. Por ejemplo, no se aplica el mismo nivel de escrutinio a un modelo que podría ser utilizado para generar spam de manera más efectiva que a uno que podría ayudar a diseñar un arma biológica.
Además, los CCLs están diseñados para ser dinámicos. A medida que la investigación avanza y se comprenden mejor los riesgos, estos umbrales pueden ajustarse para reflejar nuevos conocimientos. Esta flexibilidad es crucial en un campo que está evolucionando tan rápidamente como la IA.
fact_check Proceso de Evaluación de Riesgos: Cómo Funciona
Identificar los Critical Capability Levels es solo el primer paso. El verdadero desafío radica en evaluar continuamente los modelos para determinar cuándo se acercan o alcanzan estos umbrales. El Frontier Safety Framework de DeepMind describe un proceso de evaluación de riesgos que es a la vez riguroso y práctico.
insights Las Tres Fases de la Evaluación de Riesgos
El proceso de evaluación de riesgos de DeepMind se puede desglosar en tres fases principales:
- Identificación: DeepMind ha identificado dominios de riesgo específicos (CBRN, ciber, manipulación dañina e investigación y desarrollo de ML) donde los riesgos graves son más probables. Para cada dominio, han desarrollado escenarios específicos en los que estos riesgos podrían materializarse.
- Análisis: Central en sus evaluaciones de modelo están las "evaluaciones de alerta temprana", diseñadas para evaluar la proximidad del modelo a un CCL. Definen "umbrales de alerta" que están diseñados para indicar cuándo se podría alcanzar un CCL antes de que se realice nuevamente una evaluación de riesgos.
- Determinación de aceptación y mitigaciones: Una vez completadas las evaluaciones, determinan si el modelo ha alcanzado o alcanzará un CCL y, si es así, si necesitan implementar mitigaciones adicionales para reducir el riesgo a un nivel aceptable.
Lo que es particularmente interesante sobre este proceso es su naturaleza continua. No es algo que se hace una vez y se olvida. DeepMind realiza evaluaciones de riesgos en varios momentos durante el desarrollo del modelo, tanto antes como después del despliegue. Para versiones posteriores del modelo, realizan evaluaciones adicionales si el modelo tiene capacidades nuevas significativas o un aumento material en el rendimiento.
Este enfoque refleja una comprensión matizada de que los riesgos no son estáticos. A medida que los modelos evolucionan y se despliegan en nuevos contextos, su perfil de riesgo también cambia. El proceso de evaluación está diseñado para capturar estos cambios dinámicos y garantizar que las mitigaciones se ajusten en consecuencia.
psychology Desafíos de Alineación y Control en IA: Contexto Más Amplio
Para entender plenamente la importancia del Frontier Safety Framework, es necesario situarlo en el contexto más amplio de los desafíos de alineación y control en IA. Estos no son problemas técnicos menores; son cuestiones fundamentales que van al corazón de cómo construimos e implementamos sistemas de inteligencia artificial.
balance El Problema Fundamental de la Alineación
El "problema de alineación" se refiere al desafío de garantizar que los sistemas de IA se comporten de manera consistente con los valores e intereses humanos. A primera vista, esto puede parecer simple, pero es extraordinariamente complejo en la práctica. Los valores humanos son a menudo contradictorios, contextuales y difíciles de definir formalmente. ¿Cómo codificamos algo como "hacer lo correcto" en un sistema de IA cuando ni siquiera los humanos podemos ponernos de acuerdo sobre lo que eso significa en todas las situaciones?
Los investigadores han identificado cuatro principios clave de la alineación de IA: robustez, interpretabilidad, controlabilidad y ética (conocidos como RICE). La robustez se refiere a la capacidad de un sistema para operar de manera confiable en diversas condiciones. La interpretabilidad nos permite entender cómo y por qué un sistema de IA toma decisiones. La controlabilidad garantiza que los sistemas respondan a la intervención humana. Y la ética se refiere a la alineación con valores sociales y estándares morales.
El Riesgo de la Desalineación
Cuando los sistemas de IA no están adecuadamente alineados, pueden surgir varios tipos de riesgos. Estos incluyen sesgo y discriminación, "reward hacking" (cuando un sistema encuentra formas de maximizar su recompensa sin cumplir realmente el objetivo previsto), desinformación y polarización política, y en escenarios extremos, riesgo existencial.
Un ejemplo clásico del riesgo de desalineación es el "problema del maximizador de clips" del filósofo Nick Bostrom. En este escenario hipotético, una superinteligencia artificial programada con el objetivo de fabricar clips eventualmente transforma toda la tierra y luego porciones crecientes del espacio en instalaciones de fabricación de clips. Aunque esto suena a ciencia ficción, ilustra un punto importante: sin una alineación cuidadosa, los sistemas pueden interpretar literalmente sus objetivos de maneras que no anticipamos y que podrían tener consecuencias catastróficas.
"La desalineación entre lo que podemos especificar y lo que queremos ya ha causado daños significativos. Los diseñadores de IA a menudo se encuentran en una posición similar a la del Rey Midas, quien pidió que todo lo que tocara se convirtiera en oro, pero eventualmente murió porque la comida que tocaba también se convertía en oro." - Investigadores de la Universidad de California, Berkeley
trending_up Implicaciones para el Futuro de la Seguridad en IA
La actualización del Frontier Safety Framework de Google DeepMind no ocurre en el vacío. Es parte de un movimiento más amplio en la industria de la IA hacia enfoques más estructurados y proactivos para la seguridad. Esta tendencia tiene implicaciones significativas para cómo se desarrollará y desplegará la IA en el futuro.
public Un Enfoque Colaborativo para la Seguridad Global
Una de las implicaciones más importantes es el reconocimiento de que la seguridad de la IA es un bien público global. Como señala DeepMind en su marco, "hay ciertas mitigaciones cuyo valor social se reduce significativamente si no se aplican ampliamente a los modelos de IA fronteriza que alcanzan capacidades críticas". Esto sugiere un movimiento hacia una mayor colaboración y estandarización en las prácticas de seguridad de IA, similar a lo que hemos visto en otros campos como la seguridad nuclear o la aviación.
Otra implicación es la creciente profesionalización de la seguridad de IA como campo. Lo que antes era un nicho especializado está convirtiéndose rápidamente en una disciplina central en el desarrollo de IA. Esto se refleja en la creciente inversión en investigación de seguridad, la aparición de equipos dedicados a la seguridad en las principales empresas de IA, y el desarrollo de marcos y estándares formales.
El Rol de la Regulación
La actualización del marco de DeepMind también tiene implicaciones para la regulación de la IA. A medida que los gobiernos de todo el mundo consideran cómo regular esta tecnología, los marcos de seguridad desarrollados por la industria podrían proporcionar una base útil. De hecho, ya estamos seeing señales de esto, con regulaciones como la Ley de IA de la UE que incorporan conceptos similares a los encontrados en el Frontier Safety Framework.
Sin embargo, también hay desafíos significativos. La rapidez con que avanza la IA significa que los marcos regulatorios pueden quedar rápidamente obsoletos. Además, existe el riesgo de que la regulación se centre demasiado en riesgos específicos y conocidos, mientras pasa por alto amenazas emergentes o imprevistas. En este sentido, enfoques como el de DeepMind, que están diseñados para evolucionar con la tecnología, podrían ser particularmente valiosos.
play_circle El Frontier Safety Framework en Acción
Para comprender mejor las capacidades y el funcionamiento del Frontier Safety Framework de Google DeepMind, te invitamos a ver este video que resume sus principales características y funcionalidades:
summarize Conclusión: Reflexiones Finales
La tercera versión del Frontier Safety Framework de Google DeepMind representa un paso significativo en la evolución de la seguridad de la IA. Al expandir su alcance para abordar riesgos como la manipulación dañina y los desafíos de control, el marco reconoce la creciente complejidad de los sistemas de IA y los riesgos asociados con ellos.
auto_awesome Un Camino hacia una IA Más Segura
Lo que hace que este marco sea particularmente valioso es su naturaleza proactiva y evolutiva. En lugar de simplemente reaccionar a problemas después de que ocurren, está diseñado para identificar y abordar riesgos antes de que se conviertan en amenazas reales. Y al estar basado en evidencia y diseñado para evolucionar con nueva investigación y experiencia, tiene el potencial de mantenerse relevante incluso a medida que la IA continúa avanzando a un ritmo vertiginoso.
Sin embargo, también es importante reconocer que ningún marco, por sofisticado que sea, puede eliminar completamente los riesgos asociados con la IA avanzada. La seguridad de la IA no es un problema que pueda "resolverse" de una vez por todas; es un desafío continuo que requerirá vigilancia constante, investigación innovadora y colaboración global.
A medida que avanzamos hacia un futuro donde la IA jugará un papel cada vez más central en nuestras vidas, marcos como el de DeepMind serán esenciales para garantizar que estos sistemas se desarrollen y desplieguen de manera segura y beneficiosa. Pero también requerirán algo más: un compromiso continuo de todas las partes interesadas, desde desarrolladores e investigadores hasta responsables políticos y el público en general, para participar en un diálogo continuo sobre cómo queremos que sea el futuro de la IA.
La pregunta fundamental que enfrentamos no es simplemente "¿cómo hacemos que la IA sea segura?", sino "¿qué tipo de futuro queremos construir con la IA?". El Frontier Safety Framework de DeepMind es una herramienta importante para abordar la primera pregunta, pero la segunda requerirá una conversación mucho más amplia y profunda sobre valores, ética y el tipo de sociedad en la que queremos vivir.
"El camino hacia una AGI beneficiosa requiere no solo avances técnicos, sino también marcos sólidos para mitigar riesgos en el camino. Esperamos que nuestro Frontier Safety Framework actualizado contribuya significativamente a este esfuerzo colectivo." - Google DeepMind
En última instancia, la seguridad de la IA no es solo un desafío técnico; es un desafío humano. Requiere que pensemos cuidadosamente sobre qué valores queremos codificar en estos sistemas, cómo queremos que interactúen con nosotros, y qué límites queremos establecer. El Frontier Safety Framework de DeepMind es un paso importante en esta dirección, pero es solo el comienzo de un viaje que será uno de los definitorios de nuestro tiempo.


