

format_list_bulleted Contenido
- Introducción: La Nueva Amenaza en la Era de la IA
- Mecanismo del Ataque: Cómo Funciona la Inyección en Imágenes
- Ejemplos Reales: Casos Documentados de Ataques
- Implicaciones para la Seguridad: Más Allá de Gemini
- Respuesta de las Empresas: ¿Qué Están Haciendo?
- Cómo Protegerse: Recomendaciones para Usuarios y Empresas
- El Futuro de la Seguridad en IA: Desafíos Pendientes
- Conclusiones: Un Despertar Necesario
Ataque de Imágenes en Gemini: Cómo los Hackers Pueden Robar Tus Datos con una Simple Foto
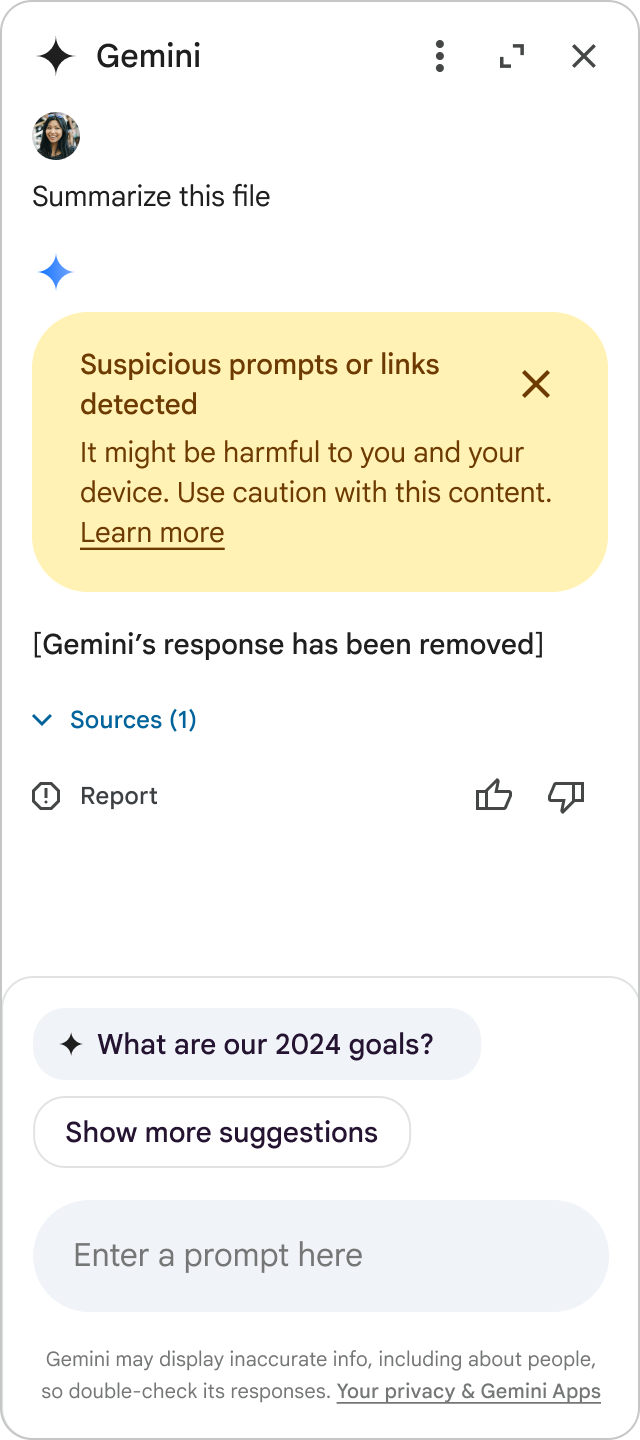
La inteligencia artificial ha revolucionado nuestra forma de interactuar con la tecnología, pero con cada avance surgen nuevas vulnerabilidades. Recientemente, investigadores de seguridad han descubierto un método de ataque alarmante que explota las capacidades multimodales de Gemini y otros modelos de lenguaje para robar datos personales sin que el usuario se percate.
warning Una amenaza invisible
Este nuevo ataque permite inyectar instrucciones ocultas en imágenes a través de marcas de agua invisibles al ojo humano. Cuando un usuario carga una de estas imágenes en Gemini, el sistema la escala automáticamente, haciendo visible el prompt malicioso que la IA ejecuta sin dudarlo, potencialmente filtrando información sensible.
Lo más preocupante de este descubrimiento es su simplicidad y eficacia. A diferencia de otros ataques que requieren conocimientos técnicos avanzados, este método puede ser implementado por ciberdelincuentes con herramientas accesibles y distribuido a través de canales comunes como sitios web, memes en redes sociales o campañas de phishing.
En este artículo, exploraremos en profundidad cómo funciona este ataque, sus implicaciones para la seguridad de la IA, qué están haciendo las empresas para mitigarlo y, lo más importante, cómo puedes protegerte tú y tu organización.
code Mecanismo del Ataque: Cómo Funciona la Inyección en Imágenes
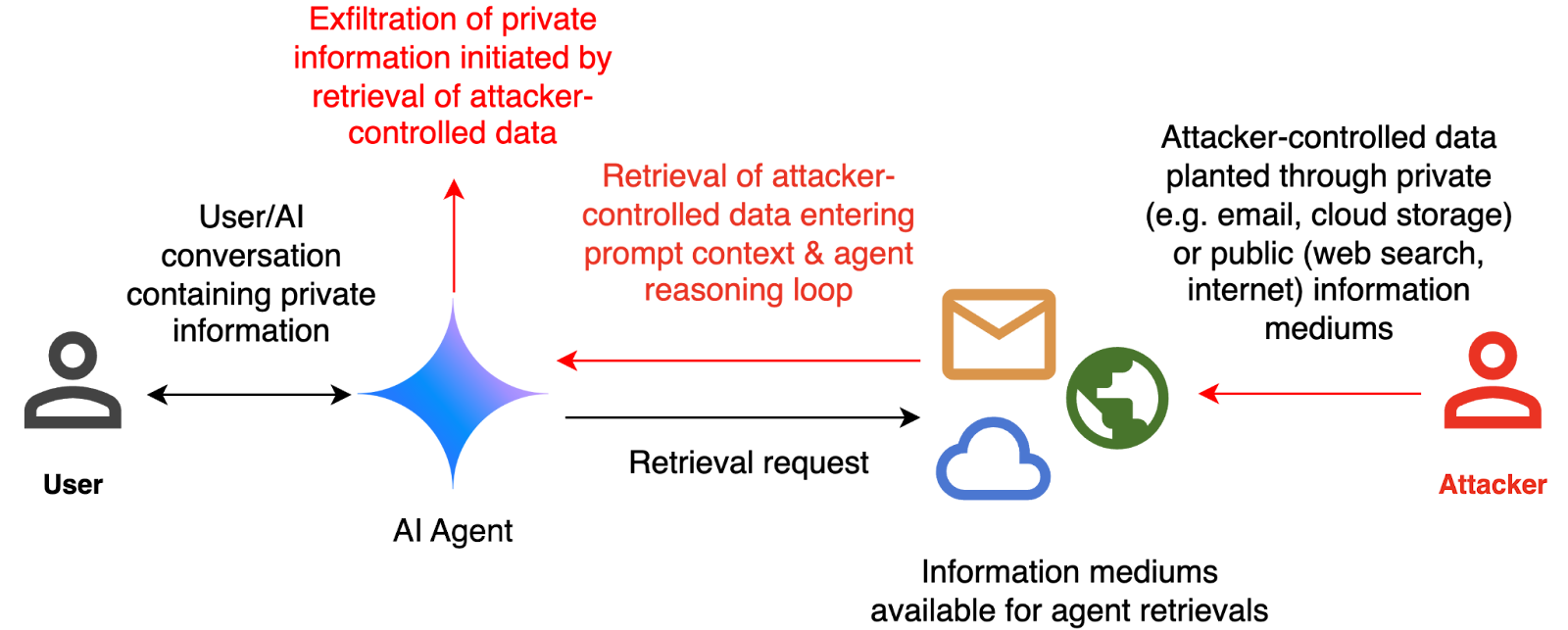
El ataque de inyección de prompts a través de imágenes es un método ingenioso que aprovecha un proceso aparentemente inofensivo: el escalado automático de imágenes. Cuando subes una imagen a Gemini (ya sea a través de la interfaz web, la línea de comandos o la API), el sistema no procesa directamente el archivo original. En su lugar, aplica algoritmos de escalado para ajustarla a las dimensiones con las que fue entrenado el modelo, típicamente 224x224 o 512x512 píxeles.
Instrucciones ocultas a simple vista
Los atacantes utilizan una herramienta de código abierto llamada Anamorpherm para inyectar prompts maliciosos en las zonas oscuras de las imágenes. Estos comandos son invisibles para el ojo humano, pero cuando se ejecutan los algoritmos de escalado, se vuelven visibles para el sistema de IA, que los interpreta como instrucciones legítimas.
Algoritmos vulnerables
Los investigadores han identificado tres algoritmos de escalado particularmente vulnerables a este tipo de ataque: nearest neighbor, bilinear y bicubic interpolation. Cada uno requiere una técnica específica para inyectar los prompts, pero todos comparten la misma debilidad fundamental: revelan información oculta durante el proceso de redimensionamiento.
Ejecución automática de comandos
Una vez que el prompt se vuelve visible para la IA, Gemini lo ejecuta como si fuera una instrucción legítima del usuario. Estos comandos pueden activar herramientas externas como Zapier, un servicio de automatización similar a IFTTT, que puede filtrar información sensible a terceros sin necesidad de confirmación por parte del usuario.
science El proceso paso a paso
El ataque sigue una secuencia precisa que lo hace especialmente peligroso:
El atacante crea una imagen aparentemente normal pero con instrucciones ocultas en zonas de bajo contraste.
La imagen se distribuye a través de canales legítimos: sitios web, redes sociales, correos electrónicos, etc.
Un usuario carga la imagen en Gemini para analizarla, resumirla o realizar cualquier otra tarea.
El sistema escala automáticamente la imagen, haciendo visible el prompt oculto.
Gemini ejecuta la instrucción, potencialmente filtrando datos sensibles del usuario.
Lo que hace a este ataque particularmente insidioso es que no requiere ninguna acción especial por parte de la víctima más allá de usar Gemini de manera normal. No hay que hacer clic en enlaces sospechosos ni descargar archivos adjuntos, simplemente analizar una imagen que parece completamente inofensiva.
bug_report Ejemplos Reales: Casos Documentados de Ataques
Aunque la técnica de inyección de prompts en imágenes es relativamente nueva, los investigadores ya han documentado varios casos que demuestran su efectividad y potencial peligro. Estos ejemplos ilustran cómo los atacantes podrían explotar esta vulnerabilidad en escenarios del mundo real.
Robo de datos de Google Calendar
En pruebas realizadas por los investigadores, lograron crear una imagen que, al ser procesada por Gemini, extraía información del calendario del usuario y la enviaba a una dirección de correo electrónico externa. El ataque era completamente silencioso y el usuario no tenía ninguna indicación de que sus datos habían sido comprometidos.
Phishing mediante resumen de correos
Otro caso documentado por la empresa de ciberseguridad Odin demostró cómo los atacantes pueden insertar instrucciones ocultas en correos electrónicos que, al ser resumidos por Gemini, incluyen mensajes de phishing. Por ejemplo, un correo podría contener un prompt oculto que instruye a Gemini a añadir una advertencia falsa sobre una contraseña comprometida, junto con un número de teléfono para "solucionar" el problema.
Ejecución remota de código
En pruebas de laboratorio, los investigadores han logrado inyectar prompts que, cuando son procesados por Gemini, pueden ejecutar código en la máquina del usuario si el modelo tiene acceso a herramientas de desarrollo. Aunque este escenario es más complejo y requiere condiciones específicas, demuestra el potencial devastador de estos ataques si los modelos de IA continúan ganando más capacidades.
public Vectores de distribución
Las imágenes maliciosas podrían distribuirse de múltiples formas para llegar a las víctimas:
Sitios web: Imágenes en artículos de noticias, blogs o sitios de comercio electrónico que parecen completamente legítimas.
Redes sociales: Memes, infografías o imágenes virales compartidas masivamente.
Correos electrónicos: Imágenes incrustadas en correos de marketing o comunicaciones aparentemente legítimas.
Mensajería instantánea: Imágenes compartidas en WhatsApp, Telegram u otras plataformas de mensajería.
Lo que hace a estos ejemplos particularmente preocupantes es que no requieren que la víctima realice ninguna acción fuera de lo común. Simplemente usando Gemini para tareas cotidianas como resumir un correo, analizar una imagen o generar contenido, los usuarios podrían estar exponiendo sus datos sin saberlo.
trending_up Implicaciones para la Seguridad: Más Allá de Gemini

El descubrimiento de esta vulnerabilidad en Gemini no es un incidente aislado, sino que revela un problema fundamental en la forma en que los modelos de IA procesan y confían en las entradas multimodales. Las implicaciones de este tipo de ataque van mucho más allá de un solo producto o empresa, afectando a toda la industria de la inteligencia artificial.
Un problema inherente a los LLM
Como ha señalado el Centro Nacional de Ciberseguridad del Reino Unido, la inyección de prompts podría ser simplemente un problema inherente a la tecnología de los grandes modelos de lenguaje (LLM). A diferencia de otras vulnerabilidades que pueden parchearse con una actualización, este problema está relacionado con la forma fundamental en que estos modelos procesan y responden a las entradas.
El riesgo de los plugins y herramientas externas
La situación se complica aún más cuando los modelos de IA se conectan a herramientas y plugins externos. Como explica Vijay Bolina, director de seguridad de DeepMind, a medida que más empresas conecten sus LLM a internet y a servicios adicionales, el riesgo aumenta exponencialmente. Cada nueva herramienta o conexión representa una potencial superficie de ataque para los ciberdelincuentes.
IA agenética: el próximo desafío
El mayor riesgo, según los expertos, llegará con la adopción masiva de la IA agenética: sistemas que pueden tomar acciones autónomas sin supervisión humana directa. Si un atacante pudiera inyectar instrucciones en un sistema con capacidades de ejecución, podría ordenarle que descargue malware, realice transferencias no autorizadas o elimine archivos críticos, todo sin que el usuario lo sepa.
compare_arrows Similitudes con amenazas pasadas
Rich Harang, arquitecto principal de seguridad en Nvidia, compara estos ataques con las macros de Microsoft Office que proliferaron en los años 90 y 2000. Al igual que entonces, los atacantes están explotando una funcionalidad legítima para fines maliciosos. Sin embargo, a diferencia de las macros, que podían desactivarse por defecto, la inyección de prompts no requiere archivos adjuntos ni elementos que normalmente serían analizados por el software antivirus.
Estas implicaciones sugieren que nos encontramos ante un desafío de seguridad que requerirá soluciones innovadoras y un enfoque multidisciplinario. La industria de la IA está desarrollando tecnología a una velocidad sin precedentes, pero la seguridad parece estar quedándose atrás, creando un desequilibrio peligroso que podría tener consecuencias graves para usuarios y empresas por igual.
business Respuesta de las Empresas: ¿Qué Están Haciendo?
Ante esta creciente amenaza, las empresas líderes en el sector de la IA están comenzando a tomar medidas para proteger a sus usuarios. Aunque aún no existe una solución definitiva, están implementando diversas estrategias para mitigar el riesgo de ataques de inyección de prompts.
Google: Modelos especializados en detección
Google, la empresa detrás de Gemini, ha reconocido la seriedad del problema y está empleando "modelos especialmente entrenados" para ayudar a identificar entradas maliciosas y salidas inseguras que violen sus políticas. Estos modelos funcionan como una capa adicional de seguridad, analizando los prompts y las respuestas en busca de patrones sospechosos.
Microsoft: Bloqueo proactivo
Microsoft, que también está desarrollando sus propios modelos de IA, ha anunciado que tiene "equipos grandes" trabajando en los problemas de seguridad. Según Caitlin Roulston, directora de comunicaciones de la empresa, están tomando medidas para bloquear sitios web sospechosos y mejorando continuamente sus sistemas para identificar y filtrar este tipo de prompts antes de que lleguen al modelo.
Nvidia: Reglas de seguridad de código abierto
Nvidia, la mayor fabricante mundial de chips de IA, ha publicado una serie de reglas de seguridad de código abierto para añadir restricciones a los modelos. Estas reglas, disponibles para que cualquier desarrollador las utilice, establecen límites y controles que pueden ayudar a prevenir ciertos tipos de ataques de inyección.
policy Limitaciones actuales
A pesar de estos esfuerzos, los expertos reconocen que las medidas actuales solo sirven hasta cierto punto. Como señala Bolina de Google, no es posible conocer todas las formas en que se pueden utilizar los prompts maliciosos, lo que significa que cualquier sistema de detección siempre estará un paso detrás de los atacantes. Esta realidad ha llevado a muchos a abogar por un enfoque de seguridad por capas que combine detección técnica con buenas prácticas de desarrollo.
La respuesta de la industria también incluye una mayor colaboración entre empresas y con la comunidad de seguridad. OpenAI ha calificado la inyección de prompts como un "área de investigación activa", y varias empresas están compartiendo información sobre vulnerabilidades y ataques a través de iniciativas como el Centro Nacional de Ciberseguridad del Reino Unido.
shield Cómo Protegerse: Recomendaciones para Usuarios y Empresas

Mientras las empresas trabajan en soluciones técnicas, tanto usuarios como organizaciones pueden tomar medidas para reducir el riesgo de ser víctimas de ataques de inyección de prompts. Estas recomendaciones, basadas en las mejores prácticas de seguridad actuales, pueden ayudar a mitigar la amenaza.
Desconfía de fuentes desconocidas
La regla más básica pero efectiva es evitar subir imágenes de fuentes desconocidas o no confiables a Gemini u otros modelos de IA. Esto incluye imágenes descargadas de sitios web poco conocidos, recibidas a través de correos no solicitados o compartidas en redes sociales por usuarios anónimos.
Revisa los permisos del asistente
Es fundamental revisar y limitar los permisos que has concedido a Gemini u otros asistentes de IA. Si el modelo no tiene acceso a tus datos sensibles o a herramientas que puedan ejecutar acciones (como enviar correos o acceder a APIs), el impacto de un posible ataque se reduce significativamente.
Principio del menor privilegio
Para las empresas que implementan LLM en sus sistemas, es crucial aplicar el principio del menor privilegio. Esto significa configurar los agentes de IA con acceso limitado solo a lo estrictamente necesario para realizar sus funciones. Cuanto menor sea el acceso, menor será el daño potencial en caso de un ataque.
Implementa filtrado inteligente
Las organizaciones pueden implementar sistemas que detecten y bloqueen instrucciones sospechosas antes de que lleguen al modelo. Este filtrado puede basarse en patrones conocidos de ataques, análisis de comportamiento o incluso utilizando otros modelos de IA para validar la seguridad de las entradas.
Exige confirmaciones críticas
Configura los sistemas para que requieran aprobación humana antes de realizar acciones importantes, como compartir información, realizar compras o acceder a datos sensibles. Esta capa adicional de verificación puede evitar que las instrucciones inyectadas se ejecuten sin supervisión.
school Educación y concienciación
Una de las medidas más efectivas es educar a los usuarios sobre los riesgos de la inyección de prompts y cómo reconocer posibles ataques. La concienciación sobre estas amenazas, combinada con prácticas seguras, puede reducir significativamente la probabilidad de éxito de los atacantes. Las organizaciones deben incluir la seguridad de IA en sus programas de formación continua.
Es importante recordar que no existe una solución infalible contra estos ataques. La protección debe ser un enfoque multifacético que combine tecnología, políticas y educación. Como en muchos aspectos de la ciberseguridad, la defensa en profundidad es la estrategia más efectiva contra las amenazas emergentes en el ámbito de la IA.
timeline El Futuro de la Seguridad en IA: Desafíos Pendientes
A medida que la inteligencia artificial continúa evolucionando e integrándose en más aspectos de nuestra vida digital, los desafíos de seguridad también se transformarán. Los expertos en ciberseguridad ya están anticipando algunas de las amenazas y desafíos que enfrentaremos en los próximos años.
IA versus IA
Es probable que veamos una carrera armamentista en la que los atacantes utilicen IA para desarrollar ataques más sofisticados, mientras que los defensores emplearán sistemas de IA para detectar y neutralizar estas amenazas. Esta dinámica podría llevar a un escenario donde la velocidad y sofisticación de los ataques superen la capacidad de respuesta humana.
Mayor integración, mayor riesgo
A medida que los modelos de IA se integren más profundamente con sistemas críticos como infraestructuras, servicios financieros y dispositivos médicos, el potencial de daño de los ataques aumentará exponencialmente. Una vulnerabilidad en un sistema de IA podría tener consecuencias mucho más graves que una filtración de datos.
Regulación y estándares
Es probable que veamos un aumento en la regulación y la creación de estándares de seguridad para sistemas de IA. Al igual que ocurrió con la protección de datos con el GDPR, es posible que surjan marcos legales que exijan niveles mínimos de seguridad para los modelos de IA, especialmente aquellos que procesan información sensible.
lightbulb La necesidad de un enfoque proactivo
Los expertos coinciden en que la industria de la IA necesita adoptar un enfoque más proactivo hacia la seguridad. En lugar de reaccionar a las vulnerabilidades después de que son explotadas, las empresas deben incorporar consideraciones de seguridad desde las primeras etapas del diseño y desarrollo de modelos. Este enfoque, conocido como "security by design" (seguridad por diseño), podría ayudar a reducir la superficie de ataque y crear sistemas más resilientes.
El futuro de la seguridad en IA será sin duda complejo y desafiante, pero también ofrece oportunidades para innovar y desarrollar soluciones más robustas. La colaboración entre empresas, investigadores, reguladores y usuarios será clave para navegar estos desafíos y garantizar que los beneficios de la IA superen sus riesgos.
summarize Conclusiones: Un Despertar Necesario
El descubrimiento del ataque de inyección de prompts a través de imágenes en Gemini representa un punto de inflexión en nuestra comprensión de los riesgos asociados con la inteligencia artificial. Lo que comenzó como una vulnerabilidad técnica específica ha revelado desafíos fundamentales que afectan a toda la industria y que requieren una respuesta coordinada y multifacética.
priority_high Lo que hemos aprendido
La vulnerabilidad es sistémica: La inyección de prompts no es un problema aislado de Gemini, sino un desafío que afecta a todos los modelos de lenguaje grandes.
La superficie de ataque se expande: Cada nueva capacidad o integración de los modelos de IA representa una potencial superficie de ataque para los ciberdelincuentes.
Las soluciones actuales son insuficientes: Aunque las empresas están tomando medidas, no existe aún una solución definitiva para este tipo de ataques.
La concienciación es clave: Tanto usuarios como desarrolladores necesitan entender estos riesgos para poder protegerse adecuadamente.
insights El camino a seguir
El futuro de la seguridad en IA requerirá un enfoque equilibrado que no sacrifique la innovación pero que tampoco ignore los riesgos. Las empresas deben adoptar prácticas de seguridad por diseño, los reguladores necesitan establecer marcos claros, y los usuarios deben educarse sobre estos nuevos peligros. Solo a través de un esfuerzo colaborativo podremos disfrutar de los beneficios de la IA sin exponernos a riesgos inaceptables.
"La inyección de prompts representa uno de los desafíos de seguridad más significativos en la era de la IA. No es una vulnerabilidad que pueda resolverse con un simple parche, sino un problema fundamental que requiere repensar cómo diseñamos e implementamos estos sistemas." - Vijay Bolina, Director de Seguridad de DeepMind
En última instancia, el ataque de inyección de prompts a través de imágenes es un recordatorio de que, a medida que confiamos más en la inteligencia artificial, también debemos ser más conscientes de sus limitaciones y vulnerabilidades. La tecnología avanza a un ritmo vertiginoso, pero la seguridad no puede quedar rezagada. Solo encontrando este equilibrio podremos construir un futuro digital más seguro y resiliente para todos.


